Posted by Suzzicks
What are "fraggles" in SEO and how do they relate to mobile-first indexing, entities, the Knowledge Graph, and your day-to-day work? In this glimpse into her 2019 MozCon talk, Cindy Krum explains everything you need to understand about fraggles in this edition of Whiteboard Friday.
Video Transcription
Hi, Moz fans. My name is Cindy Krum, and I'm the CEO of MobileMoxie, based in Denver, Colorado. We do mobile SEO and ASO consulting. I'm here in Seattle, speaking at MozCon, but also recording this Whiteboard Friday for you today, and we are talking about fraggles.

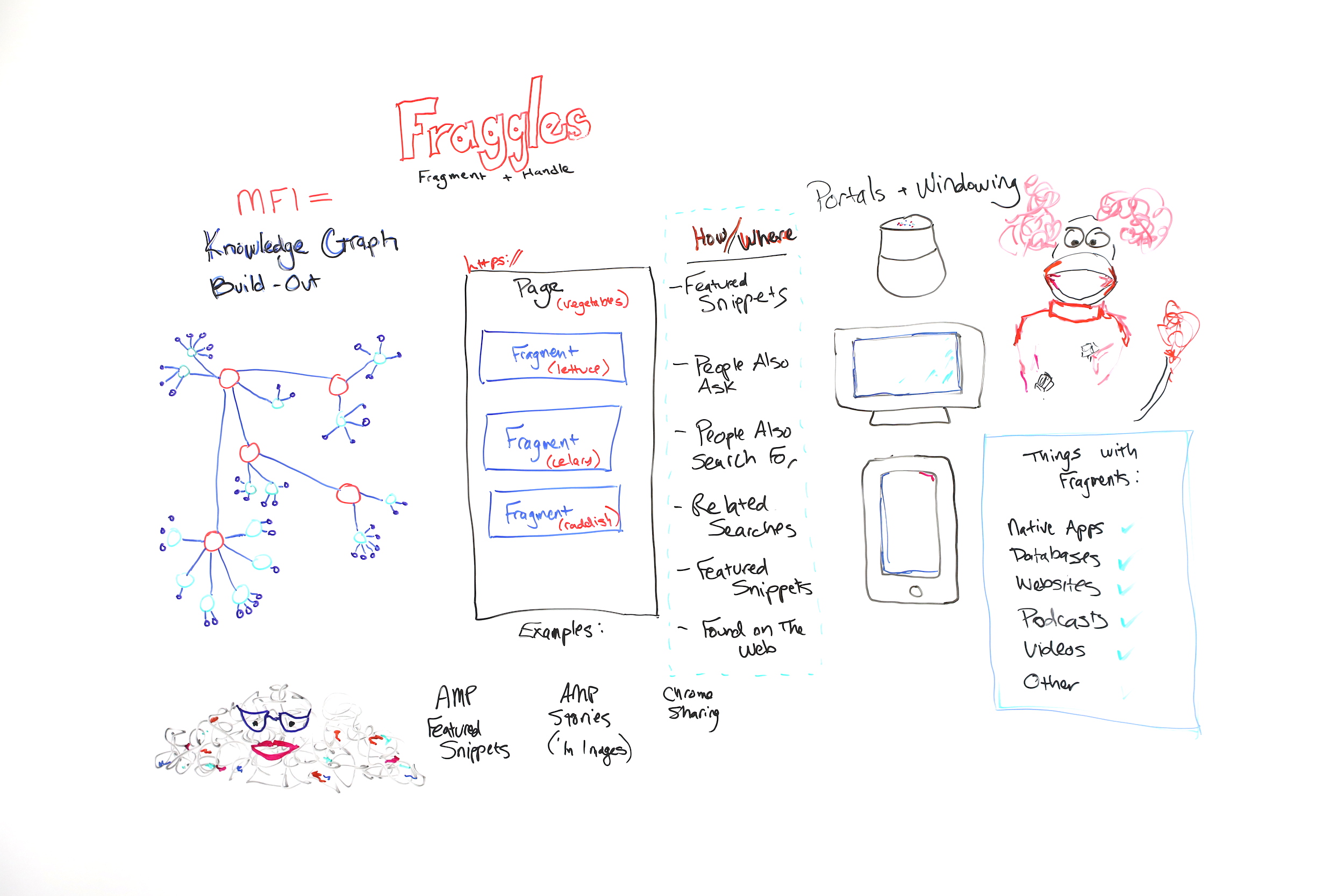
So fraggles are obviously a name that I'm borrowing from Jim Henson, who created "Fraggle Rock." But it's a combination of words. It's a combination of fragment and handle. I talk about fraggles as a new way or a new element or thing that Google is indexing.
Fraggles and mobile-first indexing
Let's start with the idea of mobile-first indexing, because you have to kind of understand that before you can go on to understand fraggles. So I believe mobile-first indexing is about a little bit more than what Google says. Google says that mobile-first indexing was just a change of the crawler.
They had a desktop crawler that was primarily crawling and indexing, and now they have a mobile crawler that's doing the heavy lifting for crawling and indexing. While I think that's true, I think there's more going on behind the scenes that they're not talking about, and we've seen a lot of evidence of this. So what I believe is that mobile-first indexing was also about indexing, hence the name.
Knowledge Graph and entities
So I think that Google has reorganized their index around entities or around specifically entities in the Knowledge Graph. So this is kind of my rough diagram of a very simplified Knowledge Graph. But Knowledge Graph is all about person, place, thing, or idea.

Nouns are entities. Knowledge Graph has nodes for all of the major person, place, thing, or idea entities out there. But it also indexes or it also organizes the relationships of this idea to this idea or this thing to this thing. What's useful for that to Google is that these things, these concepts, these relationships stay true in all languages, and that's how entities work, because entities happen before keywords.
This can be a hard concept for SEOs to wrap their brain around because we're so used to dealing with keywords. But if you think about an entity as something that's described by a keyword and can be language agnostic, that's how Google thinks about entities, because entities in the Knowledge Graph are not written up per se or their the unique identifier isn't a word, it's a number and numbers are language agnostic.
But if we think about an entity like mother, mother is a concept that exists in all languages, but we have different words to describe it. But regardless of what language you're speaking, mother is related to father, is related to daughter, is related to grandfather, all in the same ways, even if we're speaking different languages. So if Google can use what they call the "topic layer"and entities as a way to filter in information and understand the world, then they can do it in languages where they're strong and say, "We know that this is true absolutely 100% all of the time."
Then they can apply that understanding to languages that they have a harder time indexing or understanding, they're just not as strong or the algorithm isn't built to understand things like complexities of language, like German where they make really long words or other languages where they have lots of short words to mean different things or to modify different words.
Languages all work differently. But if they can use their translation API and their natural language APIs to build out the Knowledge Graph in places where they're strong, then they can use it with machine learning to also build it and do a better job of answering questions in places or languages where they're weak. So when you understand that, then it's easy to think about mobile-first indexing as a massive Knowledge Graph build-out.
We've seen this happening statistically. There are more Knowledge Graph results and more other things that seem to be related to Knowledge Graph results, like people also ask, people also search for, related searches. Those are all describing different elements or different nodes on the Knowledge Graph. So when you see those things in the search, I want you to think, hey, this is the Knowledge Graph showing me how this topic is related to other topics.
So when Google launched mobile-first indexing, I think this is the reason it took two and a half years is because they were reindexing the entire web and organizing it around the Knowledge Graph. If you think back to the AMA that John Mueller did right about the time that Knowledge Graph was launching, he answered a lot of questions that were about JavaScript and href lang.
When you put this in that context, it makes more sense. He wants the entity understanding, or he knows that the entity understanding is really important, so the href lang is also really important. So that's enough of that. Now let's talk about fraggles.
Fraggles = fragment + handle
So fraggles, as I said, are a fragment plus a handle. It's important to know that fraggles — let me go over here —fraggles and fragments, there are lots of things out there that have fragments. So you can think of native apps, databases, websites, podcasts, and videos. Those can all be fragmented.

Even though they don't have a URL, they might be useful content, because Google says its goal is to organize the world's information, not to organize the world's websites. I think that, historically, Google has kind of been locked into this crawling and indexing of websites and that that's bothered it, that it wants to be able to show other stuff, but it couldn't do that because they all needed URLs.
But with fragments, potentially they don't have to have a URL. So keep these things in mind — apps, databases and stuff like that — and then look at this.

So this is a traditional page. If you think about a page, Google has kind of been forced, historically by their infrastructure, to surface pages and to rank pages. But pages sometimes struggle to rank if they have too many topics on them.
So for instance, what I've shown you here is a page about vegetables. This page may be the best page about vegetables, and it may have the best information about lettuce, celery, and radishes. But because it's got those topics and maybe more topics on it, they all kind of dilute each other, and this great page may struggle to rank because it's not focused on the one topic, on one thing at a time.
Google wants to rank the best things. But historically they've kind of pushed us to put the best things on one page at a time and to break them out. So what that's created is this "content is king, I need more content, build more pages" mentality in SEO. The problem is everyone can be building more and more pages for every keyword that they want to rank for or every keyword group that they want to rank for, but only one is going to rank number one.

Google still has to crawl all of those pages that it told us to build, and that creates this character over here, I think, Marjory the Trash Heap, which if you remember the Fraggles, Marjory the Trash Heap was the all-knowing oracle. But when we're all creating kind of low- to mid-quality content just to have a separate page for every topic, then that makes Google's life harder, and that of course makes our life harder.
So why are we doing all of this work? The answer is because Google can only index pages, and if the page is too long or too many topics, Google gets confused. So we've been enabling Google to do this. But let's pretend, go with me on this, because this is a theory, I can't prove it. But if Google didn't have to index a full page or wasn't locked into that and could just index a piece of a page, then that makes it easier for Google to understand the relationships of different topics to one page, but also to organize the bits of the page to different pieces of the Knowledge Graph.
So this page about vegetables could be indexed and organized under the vegetable node of the Knowledge Graph. But that doesn't mean that the lettuce part of the page couldn't be indexed separately under the lettuce portion of the Knowledge Graph and so on, celery to celery and radish to radish. Now I know this is novel, and it's hard to think about if you've been doing SEO for a long time.
But let's think about why Google would want to do this. Google has been moving towards all of these new kinds of search experiences where we have voice search, we have the Google Home Hub kind of situation with a screen, or we have mobile searches. If you think about what Google has been doing, we've seen the increase in people also ask, and we've seen the increase in featured snippets.
They've actually been kind of, sort of making fragments for a long time or indexing fragments and showing them in featured snippets. The difference between that and fraggles is that when you click through on a fraggle, when it ranks in a search result, Google scrolls to that portion of the page automatically. That's the handle portion.
So handles you may have heard of before. They're kind of old-school web building. We call them bookmarks, anchor links, anchor jump links, stuff like that. It's when it automatically scrolls to the right portion of the page. But what we've seen with fraggles is Google is lifting bits of text, and when you click on it, they're scrolling directly to that piece of text on a page.
So we see this already happening in some results. What's interesting is Google is overlaying the link. You don't have to program the jump link in there. Google actually finds it and puts it there for you. So Google is already doing this, especially with AMP featured snippets. If you have a AMP featured snippet, so a featured snippet that's lifted from an AMP page, when you click through, Google is actually scrolling and highlighting the featured snippet so that you could read it in context on the page.
But it's also happening in other kind of more nuanced situations, especially with forums and conversations where they can pick a best answer. The difference between a fraggle and something like a jump link is that Google is overlaying the scrolling portion. The difference between a fraggle and a site link is site links link to other pages, and fraggles, they're linking to multiple pieces of the same long page.
So we want to avoid continuing to build up low-quality or mid-quality pages that might go to Marjory the Trash Heap. We want to start thinking in terms of can Google find and identify the right portion of the page about a specific topic, and are these topics related enough that they'll be understood when indexing them towards the Knowledge Graph.
Knowledge Graph build-out into different areas
So I personally think that we're seeing the build-out of the Knowledge Graph in a lot of different things. I think featured snippets are kind of facts or ideas that are looking for a home or validation in the Knowledge Graph. People also ask seem to be the related nodes. People also search for, same thing. Related searches, same thing. Featured snippets, oh, they're on there twice, two featured snippets. Found on the web, which is another way where Google is putting expanders by topic and then giving you a carousel of featured snippets to click through on.

So we're seeing all of those things, and some SEOs are getting kind of upset that Google is lifting so much content and putting it in the search results and that you're not getting the click. We know that 61% of mobile searches don't get a click anymore, and it's because people are finding the information that they want directly in a SERP.
That's tough for SEOs, but great for Google because it means Google is providing exactly what the user wants. So they're probably going to continue to do this. I think that SEOs are going to change their minds and they're going to want to be in those windowed content, in the lifted content, because when Google starts doing this kind of thing for the native apps, databases, and other content, websites, podcasts, stuff like that, then those are new competitors that you didn't have to deal with when it was only websites ranking, but those are going to be more engaging kinds of content that Google will be showing or lifting and showing in a SERP even if they don't have to have URLs, because Google can just window them and show them.
So you'd rather be lifted than not shown at all. So that's it for me and featured snippets. I'd love to answer your questions in the comments, and thanks very much. I hope you like the theory about fraggles.
Video transcription by Speechpad.com
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!

